2日でアプリを開発できた時代の話 – AI × Vibe Codingの力
info@appfreelife.com
アプリ副業ラボ!


從 2025 年 3 月 31 日(星期一)到 4 月 4 日(星期五),我參加了由 Google 主辦的五天密集課程「Gen AI Intensive Course with Google」,並完成了最終的 Capstone 專案。
在這個 Capstone 專案中,我們應用了所學的生成式 AI 技術,來解決自己選定的課題或實現自己的想法。
專案的主要要求是結合至少三種生成式 AI 能力來解決一個實際問題,例如:
表現優異的專案還有機會在 Kaggle 或 Google 官方社群媒體上被介紹!
在我的專案中,我開發了一個利用 Google Gemini AI 的程式,透過圖像辨識與對話紀錄分析,來評估情侶或伴侶之間的關係狀態與情感動態。
未來,我計畫在此原型基礎上,開發成任何人都能輕鬆使用的應用程式。
我會持續透過這個部落格分享開發進度、重點心得,以及如何有效運用 AI 的技巧,敬請期待!
在這個 Capstone 專案中,我建構了一個互動式流程,運用最新的生成式 AI 技術,根據圖像與對話文本來分析人際關係中的情感動態。
以下將分段詳細介紹每個部分的內容與程式碼!
在本專案中,為了避免與 Kaggle 的基礎環境發生衝突,首先移除了不必要的套件,並安裝了最新版本的必要套件。主要使用了 LangGraph 和 Google Generative AI 相關套件。
# 移除不必要的套件
!pip uninstall -qqy kfp jupyterlab libpysal thinc spacy fastai ydata-profiling google-cloud-bigquery google-generativeai
# 安裝必要的套件
!pip install -qU 'langgraph==0.3.21' 'langchain-google-genai==2.1.2' 'langgraph-prebuilt==0.1.7'
使用 Kaggle 的 Secrets 功能安全地設置 Google API 金鑰(用於 Gemini 模型),並匯入分析所需的各種程式庫。
import os
from kaggle_secrets import UserSecretsClient
GOOGLE_API_KEY = UserSecretsClient().get_secret(\"Gemini API\")
os.environ[\"GOOGLE_API_KEY\"] = GOOGLE_API_KEY
%matplotlib inline
import json
import matplotlib.pyplot as plt
import numpy as np
from google import genai
from pydantic import BaseModel, Field
from langgraph.graph import StateGraph
透過 Pydantic,對模型輸出的數據進行結構化,確保數據的品質與一致性。
總合情感評分、圖像分析結果、對話分析結果、綜合分析報告
class SummaryRating(BaseModel):
comprehensive_emotional_index: int = Field(..., ge=1, le=100, description=\"整體情感指數,範圍 1-100。")
confidence_score: int = Field(..., ge=1, le=100, description=\"信心分數,範圍 1-100。")
rating_reason: str = Field(..., description=\"評分依據的簡要說明。")
supplement_suggestion: str = Field(..., description=\"建議提供的補充資料。")
class ImageAnalysisResponse(BaseModel):
description: str = Field(..., description=\"圖片內容的文字描述。")
proximity_score: float = Field(..., ge=0, le=1, description=\"人物間的距離感分數(0 到 1)。")
eye_contact_score: float = Field(..., ge=0, le=1, description=\"眼神接觸的分數(0 到 1)。")
facial_expression_score: float = Field(..., ge=0, le=1, description=\"臉部表情情感分數(0 到 1)。")
body_touch_score: float = Field(..., ge=0, le=1, description=\"身體接觸的分數(0 到 1)。")
reason: str = Field(..., description=\"根據圖像觀察得出的分析說明。")
class ConversationAnalysisResponse(BaseModel):
positive_ratio: float = Field(..., ge=0, le=1, description=\"正向情感的比例。")
negative_ratio: float = Field(..., ge=0, le=1, description=\"負向情感的比例。")
initiative_score: float = Field(..., ge=0, le=1, description=\"對話主導程度分數(0 到 1)。")
value_alignment_score: float = Field(..., ge=0, le=1, description=\"價值觀一致程度分數(0 到 1)。")
relationship_warmth_score: float = Field(..., ge=0, le=1, description=\"關係溫暖程度分數(0 到 1)。")
toxicity_probability: float = Field(..., ge=0, le=1, description=\"潛在有害性(毒性)概率分數。")
reason: str = Field(..., description=\"根據對話與圖像分析的推論理由。")
class CompositeReport(BaseModel):
composite_reason: str = Field(..., description=\"以心理健康與關係專家視角提供的綜合評價說明。")
detailed_report: str = Field(..., description=\"詳細且具見解的綜合分析報告。")
model_config = ConfigDict(ref_template=None)
使用 gemini-2.0-flash 模型來生成內容。
client = genai.Client(api_key=GOOGLE_API_KEY)
llm = client.chats.create(model='gemini-2.0-flash')
實作了一個工具函數,用來安全地從模型回應中提取 JSON 數據,同時也考慮了錯誤處理。
def extract_json_from_response(response_text) -> dict:
#print(\"response_text:\", response_text)
# 如果回應不是字串,先轉成字串
if not isinstance(response_text, str):
response_text = str(response_text)
# 從 Markdown 格式中提取 JSON 區塊
m = re.search(r\"```json\\s*(\\{.*\\})\\s*```\", response_text, re.DOTALL)
if m:
json_str = m.group(1)
else:
# 如果找不到,從第一個 { 到最後一個 } 嘗試提取
start = response_text.find('{')
end = response_text.rfind('}')
if start != -1 and end != -1 and end > start:
json_str = response_text[start:end+1]
else:
print(\"無法在回應中找到有效的 JSON 內容。")
return {
\"comprehensive_emotional_index\": 50,
\"confidence_score\": 50,
\"rating_reason\": \"無法成功提取有效評分。\",
\"supplement_suggestion\": \"請提供更多對話資料。\"
}
try:
data = json.loads(json_str)
return data
except Exception as e:
print(\"JSON 解析錯誤:\", e)
return {
\"comprehensive_emotional_index\": 50,
\"confidence_score\": 50,
\"rating_reason\": \"無法成功提取有效評分。\",
\"supplement_suggestion\": \"請提供更多對話資料。\"
}
每個節點負責的任務包括:上傳圖片與對話資料、檢查分析條件、圖片分析、對話分析、生成報告、精細化分析,以及保存最終報告。
同時,圖像與對話的情緒得分也會透過圖表可視化,讓結果更容易理解。
本專案使用了 LangGraph 框架來視覺化「狀態圖(State Graph)」。
透過清楚顯示各節點的連結關係,使整個工作流程直覺且易於理解。實際的分析也會依照這個流程自動執行,並輸出最終分析報告。
在本專案中,流程設計採用了「狀態圖」的形式。
狀態圖會將多個處理步驟以「節點(Node)」的方式表示,並將這些節點相連成完整的工作流程。
每個節點都有特定的職能,依序執行各節點,就能完成整體流程。
以下是專案中使用的各個節點的詳細說明:
目的:
讓使用者指定要分析的圖片檔案與對話紀錄檔案的路徑,並載入至系統中。如果已有資料,會詢問是否要新增資料。
流程:
state 字典物件,供後續使用。目的:
如果有之前保存的分析結果,詢問使用者是否要將其納入此次分析中。
流程:
目的:
將上傳的圖片與對話資料整合,並使用 Google 的生成式 AI(Gemini 模型)確認是否符合最基本的分析條件。
流程:
目的:
使用 Google Gemini AI 分析每張上傳的圖片,量化與關係及情感相關的指標。
流程:
目的:
分析對話紀錄,量化情感傾向與關係品質。
流程:
目的:
整合圖片與對話的分析結果,並使用 AI 生成最終的關係評估報告。
流程:
目的:
展示生成的報告,並詢問使用者是否希望新增資訊來改善分析。
流程:
目的:
整合使用者新提供的資料(新圖片或新對話),並進行更精細的重新分析。
流程:
目的:
將最終分析報告以 JSON 格式,並附上時間戳記,保存到本地端。
流程:
# Node 1: upload_data
def upload_data(state: dict) -> dict:
# Default file paths.
default_image_path = "/kaggle/input/sample-pictures/sadcouple.png"
default_conv_path = "/kaggle/input/sampletxt/angrychat.txt"
default_new_conv_path = "/kaggle/input/sampletxt/coldchat.txt"
default_new_image_path = "/kaggle/input/sample-pictures/coldcouple.png"
# If data already exists, ask whether to append.
if state.get("image_path") is not None and state.get("conv_path") is not None:
if not isinstance(state["image_path"], list):
state["image_path"] = [state["image_path"]]
if not isinstance(state["conv_path"], list):
state["conv_path"] = [state["conv_path"]]
append_choice = input("Data already exists. Do you want to append new data? (yes/no): ").strip().lower()
if append_choice == "yes":
new_conv_path = input("Enter the path for additional conversation text (or press Enter for default or copy the datapath from dataset): ").strip()
if not new_conv_path:
new_conv_path = default_new_conv_path
try:
with open(new_conv_path, "r", encoding="utf-8") as f:
new_data = f.read()
print("Additional conversation data read successfully.")
except Exception as e:
print("Error reading additional conversation data:", e)
new_image_path = input("Enter the path for additional image (or press Enter for default or copy the datapath from dataset): ").strip()
if not new_image_path:
new_image_path = default_new_image_path
try:
with PILImage.open(new_image_path) as img:
img.verify()
print("Additional image read successfully.")
except Exception as e:
print("Error reading additional image:", e)
# Append the new data
state["conv_data"] += "\nAdditional Data:\n" + new_data
state["conv_path"].append(new_conv_path)
state["image_path"].append(new_image_path)
else:
print("Keeping original data without appending.")
else:
user_upload_image = input("Enter the image file path (or press Enter for default or copy the datapath from dataset): ").strip()
if not user_upload_image:
user_upload_image = default_image_path
user_upload_conv = input("Enter the conversation text file path (or press Enter for default or copy the datapath from dataset): ").strip()
if not user_upload_conv:
user_upload_conv = default_conv_path
try:
with open(user_upload_conv, "r", encoding="utf-8") as f:
txtdata = f.read()
print("Conversation data read successfully.")
except Exception as e:
print("Error reading conversation data:", e)
txtdata = ""
try:
with PILImage.open(user_upload_image) as img:
img.verify()
print("Image loaded successfully.")
except Exception as e:
print("Error loading image:", e)
state["conv_data"] = txtdata
state["image_path"] = [user_upload_image]
state["conv_path"] = [user_upload_conv]
if not txtdata.strip():
supplement = input("Conversation text is empty. Please provide missing data: ").strip()
state["previous_data"] = supplement # Initialize or append as needed.
#print("Uploaded conversation data:")
#print(state["conv_data"])
print("Image file paths:", state["image_path"])
print("Conversation file paths:", state["conv_path"])
return state
# Node 2: use_existing_info
def use_existing_info(state: dict) -> dict:
report_files = glob.glob("analysis_report_*.json")
if not report_files:
print("Step2 - No existing reports found; skipping existing info step.")
state["previous_data"] = None
return state
answer = input("Existing report file detected. Use previous info for further analysis? (yes/no): ").strip().lower()
if answer != "yes":
state["previous_data"] = None
print("Not using previous info.")
else:
print("Using existing info. Choose one of the following report files:")
for idx, file in enumerate(report_files):
print(f"{idx+1}. {file}")
try:
choice = int(input("Enter the report number: "))
if 1 <= choice <= len(report_files):
selected_file = report_files[choice - 1]
with open(selected_file, "r", encoding="utf-8") as f:
previous_data = json.load(f)
state["previous_data"] = previous_data
print(f"Selected {selected_file} as previous info.")
else:
print("Choice out of range; not using previous info.")
state["previous_data"] = None
except Exception as e:
print("Input error; not using previous info.", e)
state["previous_data"] = None
return state
# For print text color
BLUE = "\033[94m"
RED = "\033[91m"
GREEN = "\033[92m"
RESET = "\033[0m"
# Node 3: check_requirements
def check_requirements(state: dict) -> dict:
photo_prompt = """
Please carefully analyze this image and describe:
- The physical proximity between the subjects.
- Facial expressions.
- Eye contact.
- Any physical touch.
Provide a brief textual description.
"""
image_list = state.get("image_path", [])
all_photo_description = ""
if image_list:
for img_path in image_list:
with PILImage.open(img_path) as img:
photo_response = client.models.generate_content(
model='gemini-2.0-flash',
contents=[img, photo_prompt]
)
try:
photo_desc = photo_response.text.strip()
except Exception:
photo_desc = "Image description is not available."
all_photo_description += f"[{img_path}]:\n{photo_desc}\n\n"
else:
all_photo_description = "No image data available."
conv_text = state.get("conv_data", "")
previous_text = state.get("previous_data", "")
if isinstance(previous_text, dict):
previous_text = json.dumps(previous_text, ensure_ascii=False)
all_text = "Image Descriptions:\n" + all_photo_description + "\n\nConversation Text:\n" + conv_text
if previous_text:
all_text += "\n\nSupplemental Data:\n" + previous_text
overall_prompt = (
"Based on the following description, provide an overall emotional index (1-100), a confidence score (1-100), a one-sentence rationale, and a suggestion for additional input.\n"
"Return in pure JSON format as follows:\n"
'{\n'
' "comprehensive_emotional_index": number,\n'
' "confidence_score": number,\n'
' "rating_reason": "summary sentence",\n'
' "supplement_suggestion": "additional info suggestion"\n'
'}\n'
"Description:\n" + all_text
)
output_config = types.GenerateContentConfig(
temperature=0.0,
response_mime_type="application/json",
response_schema=SummaryRating,
)
#print("Combined description for analysis:\n", all_text)
overall_response = client.models.generate_content(
model="gemini-2.0-flash",
contents=[overall_prompt],
config=output_config
)
#print("Original response:", overall_response)
overall_data = extract_json_from_response(overall_response.text)
print(f"\n{BLUE}===== Checking the Quality of the Uploaded Document ====={RESET}\n")
comprehensive_emotional_index = overall_data.get("comprehensive_emotional_index", "N/A")
confidence_score = overall_data.get("confidence_score", "N/A")
rating_reason = overall_data.get("rating_reason", "No reason provided.")
supplement_suggestion = overall_data.get("supplement_suggestion", "No suggestion provided.")
print(f"{BLUE}【Quick Comprehensive Relationship Analysis】{RESET}")
print(f"{comprehensive_emotional_index}\n")
print(f"{BLUE}【Confidence Score】{RESET}")
print(f"{GREEN}{confidence_score}{RESET} (70 or above is acceptable)\n")
print(f"{BLUE}【Rating Reason】{RESET}")
print(f"{rating_reason}\n")
print(f"{BLUE}【Supplement Suggestion】{RESET}")
print(f"{supplement_suggestion}\n")
# Decide whether the requirements are met based on the confidence_score
if overall_data.get("confidence_score", 0) < 70:
suggestion = overall_data.get("supplement_suggestion", "Please provide additional data to improve confidence score.")
print(f"Confidence score ({overall_data.get('confidence_score')}) is below 70; please provide additional data. Suggestion: {suggestion}")
state["requirements_met"] = False
else:
state["requirements_met"] = True
# Save the overall rating data into state for further use
state["overall_rating"] = overall_data
return state
# Node 4: analyze_image
def analyze_image(state: dict) -> dict:
image_paths = state.get("image_path", [])
prompt = (
"Analyze this image with the following requirements:\n"
"- Provide a brief description of the image.\n"
"- Assign a proximity_score (0 to 1).\n"
"- Assign an eye_contact_score (0 to 1).\n"
"- Assign a facial_expression_score (0 to 1).\n"
"- Assign a body_touch_score (0 to 1).\n"
"- Provide a short rationale.\n"
"Return the result as JSON conforming to the provided schema."
)
results = []
for img_path in image_paths:
try:
with PILImage.open(img_path) as img:
output_config = types.GenerateContentConfig(
temperature=0.0,
response_mime_type="application/json",
response_schema=ImageAnalysisResponse,
)
photo_response = client.models.generate_content(
model='gemini-2.0-flash',
contents=[img, prompt],
config=output_config
)
image_result = json.loads(photo_response.text)
results.append(image_result)
except Exception as e:
results.append({
"description": "No analysis result available.",
"proximity_score": 0.5,
"eye_contact_score": 0.5,
"facial_expression_score": 0.5,
"body_touch_score": 0.5,
"reason": f"Analysis failed: {str(e)}"
})
state["image_analysis"] = results
return state
# Node 5: analyze_conversation
def analyze_conversation(state: dict) -> dict:
conv_text = state.get("conv_data", "")
previous_text = state.get("previous_data", "")
if isinstance(previous_text, dict):
previous_text = json.dumps(previous_text, ensure_ascii=False)
all_text = "Conversation Text:\n" + conv_text
if previous_text:
all_text += "\n\nSupplemental Data:\n" + previous_text
text_prompt = (
"Analyze the following conversation text. Evaluate:\n"
"1. Positive and negative sentiment ratios.\n"
"2. Initiative (who speaks first more often), producing an initiative_score (0-1).\n"
"3. Value alignment regarding major values, producing value_alignment_score (0-1).\n"
"4. Relationship warmth (0-1).\n"
"5. Probability of toxic behavior (0-1, lower means less likely).\n"
"Return in JSON format as follows:\n"
'{\n'
' "sentiment_summary": {"positive_ratio": 0.7, "negative_ratio": 0.1},\n'
' "initiative_score": 0.6,\n'
' "value_alignment_score": 0.8,\n'
' "relationship_warmth_score": 0.85,\n'
' "toxicity_probability": 0.15,\n'
' "reason": "Analysis rationale."\n'
'}\n'
"Conversation text:\n" + all_text
)
output_config = types.GenerateContentConfig(
temperature=0.0,
response_mime_type="application/json",
response_schema=ConversationAnalysisResponse,
)
conversation_response = client.models.generate_content(
model="gemini-2.0-flash",
contents=[text_prompt],
config=output_config
)
conversation_result = json.loads(conversation_response.text)
state["conversation_analysis"] = conversation_result
return state
# Node 6: generate_report
def generate_report(state: dict) -> dict:
# ---------------------------
# Retrieve image analysis results (list of dicts)
image_analysis_list = state.get("image_analysis", [])
if not image_analysis_list:
avg_proximity = avg_eye_contact = avg_facial = avg_body_touch = 0.5
image_reason = "No image analysis data available."
else:
proximity_scores = [img.get("proximity_score", 0.5) for img in image_analysis_list]
eye_contact_scores = [img.get("eye_contact_score", 0.5) for img in image_analysis_list]
facial_scores = [img.get("facial_expression_score", 0.5) for img in image_analysis_list]
body_touch_scores = [img.get("body_touch_score", 0.5) for img in image_analysis_list]
avg_proximity = sum(proximity_scores) / len(proximity_scores)
avg_eye_contact = sum(eye_contact_scores) / len(eye_contact_scores)
avg_facial = sum(facial_scores) / len(facial_scores)
avg_body_touch = sum(body_touch_scores) / len(body_touch_scores)
reasons = [img.get("reason", "") for img in image_analysis_list if img.get("reason")]
image_reason = ";".join(reasons) if reasons else "No image analysis rationale available."
image_composite = (avg_proximity + avg_eye_contact + avg_facial + avg_body_touch) / 4
# ---------------------------
# Retrieve conversation analysis results (dictionary)
conv_data = state.get("conversation_analysis", {})
sentiment = conv_data.get("sentiment_summary", {})
positive_ratio = sentiment.get("positive_ratio", 0.5)
initiative_score = conv_data.get("initiative_score", 0.5)
value_alignment_score = conv_data.get("value_alignment_score", 0.5)
relationship_warmth_score = conv_data.get("relationship_warmth_score", 0.5)
toxicity_probability = conv_data.get("toxicity_probability", 0.5)
conv_reason = conv_data.get("reason", "No conversation analysis rationale available.")
conv_composite = (initiative_score + value_alignment_score + relationship_warmth_score + (1 - toxicity_probability) + positive_ratio) / 5
# ---------------------------
# Calculate overall composite score (40% image, 60% conversation)
overall_composite = 0.4 * image_composite + 0.6 * conv_composite
overall_rating = round(overall_composite * 100)
base_composite_reason = f"From image analysis: {image_reason}; From conversation analysis: {conv_reason}."
# ---------------------------
# Prepare metrics for plotting.
image_metrics = ["Proximity", "Eye Contact", "Facial Expression", "Body Touch"]
image_values = [avg_proximity, avg_eye_contact, avg_facial, avg_body_touch]
conv_metrics = ["Initiative", "Value Alignment", "Relationship Warmth", "Positivity", "1 - Toxicity"]
conv_values = [initiative_score, value_alignment_score, relationship_warmth_score, positive_ratio, 1 - toxicity_probability]
# Unified chart function call.
chart_filename = display_chart(image_metrics, image_values, conv_metrics, conv_values, overall_rating)
# ---------------------------
# Combine conversation text and supplemental data.
conv_text = state.get("conv_data", "")
previous_text = state.get("previous_data", "")
all_text = "Conversation Text:\n" + conv_text
if previous_text:
if not isinstance(previous_text, str):
previous_text = json.dumps(previous_text, ensure_ascii=False, indent=2)
all_text += "\n\nSupplemental Data:\n" + previous_text
# ---------------------------
# Build prompt to call LLM for composite report.
prompt = (
"You are an expert psychologist and relationship counselor. Please use plain and clear language to analyze the data "
"provided below and generate:\n"
"1. A 'composite_reason': a brief, bullet-point summary of the key observations from the image analysis and conversation analysis.\n"
"2. A 'detailed_report': a detailed explanation of the current relationship status, highlighting strengths, issues, and practical recommendations for improvement.\n\n"
"【Image Analysis Rationale】\n"
f"{image_reason}\n\n"
"【Conversation Analysis Rationale】\n"
f"{conv_reason}\n\n"
"【Image Analysis Data】\n"
f"{json.dumps(image_analysis_list, ensure_ascii=False, indent=2)}\n\n"
"【Conversation Data】\n"
f"{all_text}\n\n"
"Return the result in the following JSON format without any extra text:\n"
'{\n'
' "composite_reason": "Your summary here",\n'
' "detailed_report": "Your detailed analysis and recommendations here"\n'
'}'
)
output_config = types.GenerateContentConfig(
temperature=0.0,
response_mime_type="application/json",
response_schema=CompositeReport,
)
llm_response = client.models.generate_content(
model="gemini-2.0-flash",
contents=[prompt],
config=output_config
)
try:
composite_data = json.loads(llm_response.text)
except Exception as e:
composite_data = {
"composite_reason": base_composite_reason,
"detailed_report": (
f"Preliminary Analysis: Overall rating is {overall_rating} out of 100. "
"The data suggests communication and emotional connection issues. "
"It is recommended that both parties work on open communication, rebuild trust, and consider professional counseling if needed."
)
}
composite_reason_final = composite_data.get("composite_reason", base_composite_reason)
detailed_report_final = composite_data.get("detailed_report", "")
# ---------------------------
# Assemble the final comprehensive report.
final_insights = detailed_report_final
report = {
"image_analysis": image_analysis_list,
"conversation_analysis": conv_data,
"previous_data": state.get("previous_data"),
"overall_composite_score": overall_rating,
"composite_reason": composite_reason_final,
"chart_file": chart_filename,
"detailed_report": final_insights
}
state["report"] = report
return state
# Node 7: guidance
def guidance(state: dict) -> dict:
report = state.get("report", {})
print("\n===== Composite Analysis Report =====\n")
# Overall score
overall_score = report.get("overall_composite_score", "N/A")
print(f"{BLUE}【Overall Emotional Rating】{RESET}")
print(f"Your overall relationship rating is {RED}{overall_score}{RESET} out of 100.\n")
# Key observations
composite_reason = report.get("composite_reason", "No summary available.")
print(f"{BLUE}【Summary of Key Observations】{RESET}")
print(f"{composite_reason}\n")
# Detailed report
detailed_report = report.get("detailed_report", "No detailed report available.")
print(f"{BLUE}【Detailed Analysis & Recommendations】{RESET}")
print(f"{detailed_report}\n")
# Chart file
chart_file = report.get("chart_file", "No chart file.")
print(f"{BLUE}【Chart File】{RESET}")
print(f"{chart_file}\n")
need_more = input("Would you like to add new file data (photo or text) for further report refinement? (yes/no): ").strip().lower()
if need_more == "yes":
state["branch"] = "refined"
else:
state["branch"] = "final"
return state
# Node 8: refine analysis
def refine_analysis(state: dict) -> dict:
"""
Incorporate new file data (photo and text) provided by the client,
update supplemental data, and re-calculate image and conversation analyses based on the new inputs.
Then, call the LLM to generate an updated composite report.
The final output report follows the same format as Nodes 5-7, with branch set to "final".
"""
new_data_str = ""
# Process new photo file (optional)
new_photo_path = input("Enter new photo file path (or press Enter if not applicable, or copy the file path from your dataset): ").strip()
if new_photo_path:
new_image_analysis = analyze_image_for_file(new_photo_path)
image_analysis_list = state.get("image_analysis", [])
image_analysis_list.append(new_image_analysis)
state["image_analysis"] = image_analysis_list
new_data_str += f"New photo file provided and analyzed: {new_photo_path}. "
# Process new text file for conversation (optional)
new_text_path = input("Enter new text file path (or press Enter if not applicable, or copy the file path from your dataset): ").strip()
if new_text_path:
try:
with open(new_text_path, "r", encoding="utf-8") as f:
new_text = f.read()
new_data_str += f"New text data provided from {new_text_path}:\n{new_text}\n"
# Reanalyze conversation using the new text data.
new_conv_analysis = analyze_conversation_for_text(new_text)
state["conversation_analysis"] = new_conv_analysis
# Update the raw conversation text to include new text.
conv_text = state.get("conv_data", "")
state["conv_data"] = conv_text + "\n\n" + new_text
except Exception as e:
print("Error reading new text file:", e)
# Update supplemental data with new file information.
if new_data_str:
original_previous_data = state.get("previous_data", "")
combined_data = (original_previous_data + "\n*** Additional Data (High Weight) ***\n" + new_data_str) if original_previous_data else new_data_str
state["previous_data"] = combined_data
# Set branch to "final" so the flow ends with the final report.
state["branch"] = "final"
# --- Recalculate key metrics using updated data ---
# For image analysis:
image_analysis_list = state.get("image_analysis", [])
if image_analysis_list:
proximity_scores = [img.get("proximity_score", 0.5) for img in image_analysis_list]
eye_contact_scores = [img.get("eye_contact_score", 0.5) for img in image_analysis_list]
facial_scores = [img.get("facial_expression_score", 0.5) for img in image_analysis_list]
body_touch_scores = [img.get("body_touch_score", 0.5) for img in image_analysis_list]
avg_proximity = sum(proximity_scores) / len(proximity_scores)
avg_eye_contact = sum(eye_contact_scores) / len(eye_contact_scores)
avg_facial = sum(facial_scores) / len(facial_scores)
avg_body_touch = sum(body_touch_scores) / len(body_touch_scores)
else:
avg_proximity = avg_eye_contact = avg_facial = avg_body_touch = 0.5
image_composite = (avg_proximity + avg_eye_contact + avg_facial + avg_body_touch) / 4
# For conversation analysis:
conv_data = state.get("conversation_analysis", {})
sentiment = conv_data.get("sentiment_summary", {})
positive_ratio = sentiment.get("positive_ratio", 0.5)
initiative_score = conv_data.get("initiative_score", 0.5)
value_alignment_score = conv_data.get("value_alignment_score", 0.5)
relationship_warmth_score = conv_data.get("relationship_warmth_score", 0.5)
toxicity_probability = conv_data.get("toxicity_probability", 0.5)
conv_composite = (initiative_score + value_alignment_score + relationship_warmth_score + (1 - toxicity_probability) + positive_ratio) / 5
overall_composite = 0.4 * image_composite + 0.6 * conv_composite
overall_rating = round(overall_composite * 100)
# Prepare base composite reason (using prior report if available)
report = state.get("report", {})
base_composite_reason = report.get("composite_reason", "Original composite observations unavailable.")
# Retrieve conversation raw text and supplemental data.
conv_text = state.get("conv_data", "")
previous_data = state.get("previous_data", "")
all_text = "Conversation Text:\n" + conv_text
if previous_data:
if not isinstance(previous_data, str):
previous_data = json.dumps(previous_data, ensure_ascii=False, indent=2)
all_text += "\n\nSupplemental Data:\n" + previous_data
# --- Build prompt for LLM to generate updated composite report ---
new_prompt = (
"You are an expert psychologist and relationship counselor. Based on the updated data provided below, please generate an updated composite report. "
"The newly provided file data should be given higher weight in the evaluation. Your response must include:\n"
"1. 'composite_reason': A concise bullet-point summary of key observations derived from the image and conversation analyses, highlighting any new insights due to the additional data.\n"
"2. 'detailed_report': A comprehensive analysis of the current relationship status, including strengths, issues, and specific, actionable recommendations for improvement.\n\n"
"【Original Composite Observations】\n"
f"{base_composite_reason}\n\n"
"【Image Analysis Data】\n"
f"{json.dumps(image_analysis_list, ensure_ascii=False, indent=2)}\n\n"
"【Conversation Data】\n"
f"{all_text}\n\n"
"Return your response in JSON format as follows (with no extra text):\n"
'{\n'
' "composite_reason": "Your revised composite reason",\n'
' "detailed_report": "Your revised detailed report"\n'
'}'
)
output_config = types.GenerateContentConfig(
temperature=0.0,
response_mime_type="application/json",
response_schema=CompositeReport,
)
llm_response = client.models.generate_content(
model="gemini-2.0-flash",
contents=[new_prompt],
config=output_config
)
try:
new_composite_data = json.loads(llm_response.text)
except Exception as e:
new_composite_data = {
"composite_reason": base_composite_reason,
"detailed_report": (
f"Preliminary Analysis: The overall rating remains {overall_rating} out of 100. Further professional consultation is advised."
)
}
refined_composite_reason = new_composite_data.get("composite_reason", base_composite_reason)
refined_detailed_report = new_composite_data.get("detailed_report", "")
final_insights = refined_detailed_report
final_report = {
"image_analysis": image_analysis_list,
"conversation_analysis": conv_data,
"previous_data": state.get("previous_data"),
"overall_composite_score": overall_rating,
"composite_reason": refined_composite_reason,
"chart_file": report.get("chart_file", "N/A"),
"detailed_report": final_insights
}
state["report"] = final_report
# Recompute metrics for chart display.
if image_analysis_list:
proximity_scores = [img.get("proximity_score", 0.5) for img in image_analysis_list]
eye_contact_scores = [img.get("eye_contact_score", 0.5) for img in image_analysis_list]
facial_scores = [img.get("facial_expression_score", 0.5) for img in image_analysis_list]
body_touch_scores = [img.get("body_touch_score", 0.5) for img in image_analysis_list]
avg_proximity = sum(proximity_scores) / len(proximity_scores)
avg_eye_contact = sum(eye_contact_scores) / len(eye_contact_scores)
avg_facial = sum(facial_scores) / len(facial_scores)
avg_body_touch = sum(body_touch_scores) / len(body_touch_scores)
else:
avg_proximity = avg_eye_contact = avg_facial = avg_body_touch = 0.5
image_metrics = ["Proximity", "Eye Contact", "Facial Expression", "Body Touch"]
image_values = [avg_proximity, avg_eye_contact, avg_facial, avg_body_touch]
initiative_score = conv_data.get("initiative_score", 0.5)
value_alignment_score = conv_data.get("value_alignment_score", 0.5)
relationship_warmth_score = conv_data.get("relationship_warmth_score", 0.5)
sentiment = conv_data.get("sentiment_summary", {})
positive_ratio = sentiment.get("positive_ratio", 0.5)
toxicity_probability = conv_data.get("toxicity_probability", 0.5)
conv_metrics = ["Initiative", "Value Alignment", "Relationship Warmth", "Positivity", "1 - Toxicity"]
conv_values = [initiative_score, value_alignment_score, relationship_warmth_score, positive_ratio, 1 - toxicity_probability]
chart_filename = display_chart(image_metrics, image_values, conv_metrics, conv_values, overall_rating)
# After updating state["report"], print it out elegantly:
report = state.get("report", {})
print("\n===== Refined Composite Analysis Report =====\n")
# Overall score
overall_score = report.get("overall_composite_score", "N/A")
print(f"{BLUE}【Overall Emotional Rating】{RESET}")
print(f"Your overall relationship rating is {RED}{overall_score}{RESET} out of 100.\n")
# Key observations
composite_reason = report.get("composite_reason", "No summary available.")
print(f"{BLUE}【Summary of Key Observations】{RESET}")
print(f"{composite_reason}\n")
# Detailed report
detailed_report = report.get("detailed_report", "No detailed report available.")
print(f"{BLUE}【Detailed Analysis & Recommendations】{RESET}")
print(f"{detailed_report}\n")
# Chart file
chart_file = report.get("chart_file", "No chart file.")
print(f"{BLUE}【Chart File】{RESET}")
print(f"{chart_file}\n")
state["report"]["chart_file"] = chart_filename
return state
# Node 9: save_report
def save_report(state: dict) -> dict:
report = state.get("report", {})
filename = f"analysis_report_{datetime.datetime.now().strftime('%Y%m%d_%H%M%S')}.json"
try:
with open(filename, "w", encoding="utf-8") as f:
json.dump(report, f, ensure_ascii=False, indent=2)
print(f"Final Report saved to {filename}")
except Exception as e:
print("Failed to save report:", e)
return state
分岐函數負責根據「信賴度分數」來控制流程,決定是要求使用者提供更多資料,還是繼續進行後續分析。
# 正確的 branch_requirements 函數
def branch_requirements(state: dict) -> Literal["analyze_image", "upload_data"]:
return "analyze_image" if state.get("requirements_met") else "upload_data"
# 根據 guidance 結果進行分岐
def branch_guidance(state: dict) -> Literal["refine_analysis", "save_report"]:
return "refine_analysis" if state.get("branch") == "refined" else "save_report"
將每個流程步驟註冊成節點,並使用條件分岐控制工作流程的順序。
def build_state_graph():
graph_builder = StateGraph(dict)
graph_builder.add_node("upload_data", upload_data)
graph_builder.add_node("use_existing_info", use_existing_info)
graph_builder.add_node("check_requirements", check_requirements)
graph_builder.add_node("analyze_image", analyze_image)
graph_builder.add_node("analyze_conversation", analyze_conversation)
graph_builder.add_node("generate_report", generate_report)
graph_builder.add_node("guidance", guidance)
graph_builder.add_node("refine_analysis", refine_analysis)
graph_builder.add_node("save_report", save_report)
graph_builder.add_edge(START, "upload_data")
graph_builder.add_edge("upload_data", "use_existing_info")
graph_builder.add_edge("use_existing_info", "check_requirements")
graph_builder.add_conditional_edges("check_requirements", branch_requirements)
graph_builder.add_edge("analyze_image", "analyze_conversation")
graph_builder.add_edge("analyze_conversation", "generate_report")
graph_builder.add_edge("generate_report", "guidance")
graph_builder.add_conditional_edges("guidance", branch_guidance)
graph_builder.add_edge("refine_analysis", "save_report")
graph_builder.add_edge("save_report", END)
return graph_builder.compile()
使用 Mermaid 來將整個流程可視化,提升分析過程的透明度。
完成流程圖之後,會執行流程,生成最終的分析報告。
from IPython.display import Image, display
# 從之前定義的節點與邊構建流程圖
graph = build_state_graph()
透過這個專案,我展示了生成式 AI 技術如何能有效應用於深層次的人際關係分析。
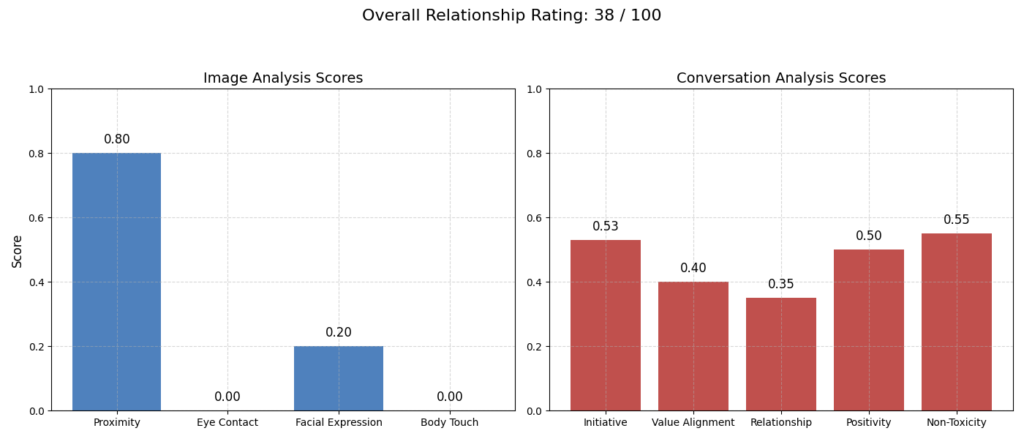
你的整體關係評分為 38 分(滿分 100 分)。
關鍵觀察結果如下:
本專案旨在透過 AI 技術,協助情侶或伴侶分析並改善他們之間的溝通與關係動態。
例如:
針對這些模糊又難以明確描述的困擾,本專案運用 AI 進行客觀分析,並提出具體可行的第一步改善建議。
在本專案中,我使用了 Google 最先進的生成式 AI 技術(Gemini 模型),進行兩種主要分析:
這些分析結果會被整合起來,AI 最後會以報告形式,提供關係評估與實用建議。
(文中也包含了載入圖片並取得 AI 分析結果的範例程式碼。)
限制包括:
我計劃將本專案開發成一款智慧型手機應用程式,讓任何人都能輕鬆使用。
未來的目標包括:
隨著科技持續進步,我希望 AI 驅動的人際關係分析能變得更準確且更深入。